Analysing text data by time-series feature engineering
Dr Andreas W. Kempa-Liehr, Senior Lecturer, Engineering Science; Yichen Tang, Graduate Teaching Assistant, Computer Science; Dr Kelly Blincoe, Senior Lecturer, Department of Electrical, Computer and Software Engineering
Language in its diversity and specificity is one of the key cultural characteristics of humanity. Driven by the increasing volume of digitized written and spoken language, the fields of computational linguistics and natural language processing transform written and spoken language to extract meaning.
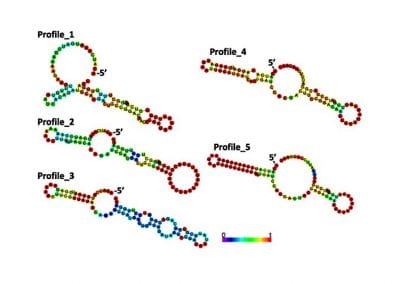
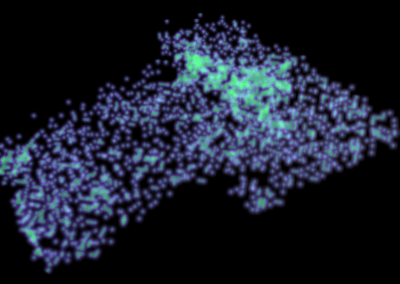
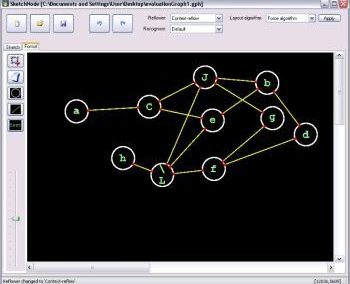
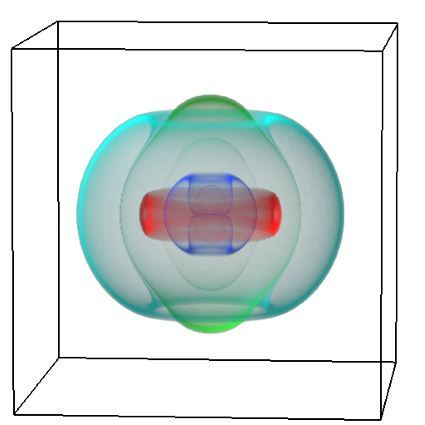
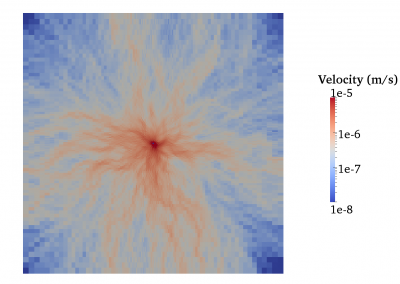
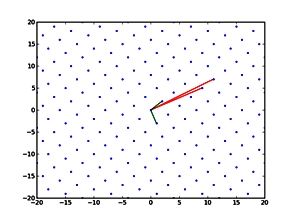
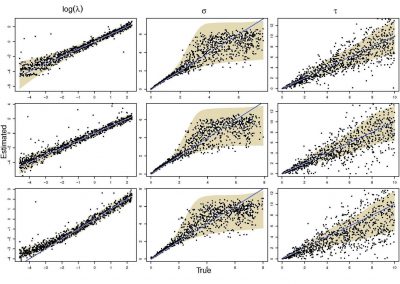
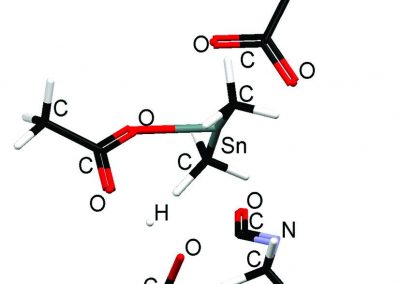
Both written and spoken language are temporally encoded information. This is quite clear for spoken language, which for example might be recorded as an electrical signal of a microphone. Yet, written language appears static due to its encoding in words and symbols. Our recent work has shown that the classical approaches for feature engineering for text samples can be extended by integrating techniques which have been introduced in the context of time series classification and signal processing (Tang et al., 2020). The general idea of our feature engineering approach is to tokenize the text samples under consideration and map each token to a number, which measures a specific property of the token. Consequently, each text sample becomes a language time series, which is generated from consecutively emitted tokens, and time is represented by the position of the respective token within the text sample (Fig. 1). The resulting language time series can be characterised by collections of established time series feature extraction algorithms from time series analysis and signal processing (Christ et al., 2018). Our approach maps each text sample (irrespective of its original length) to 3970 stylometric features.
Our proposed feature engineering technique for short text data is applied to two different corpora, which are discussed as examples for authorship attribution problems: the Federalist Papers data set (Hamilton et al., 1998) and the Spooky Books data set (Kaggle, 2018). The latter comprises 19579 sentences from spooky novels of three famous authors: Edgar Allan Poe (EAP), HP Lovecraft (HPL) and Mary Wollstonecraft Shelley (MWS), so both the genre and the topic of the documents have been controlled.
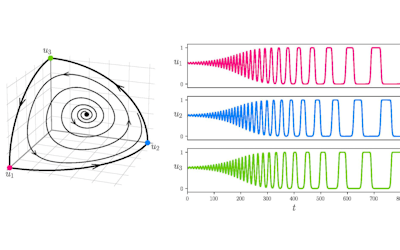
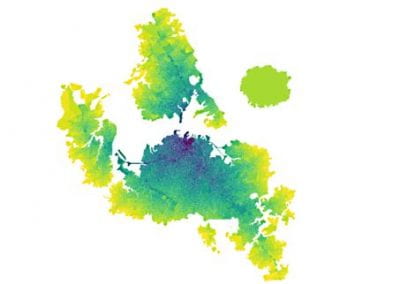
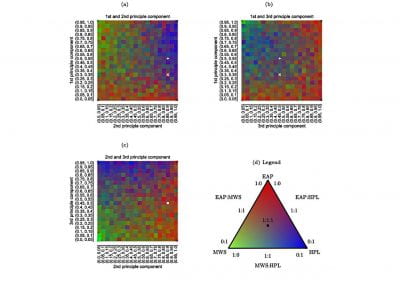
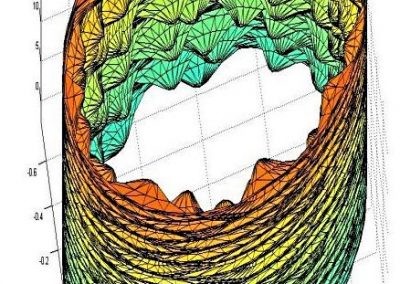
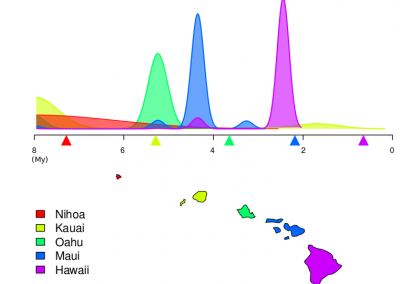
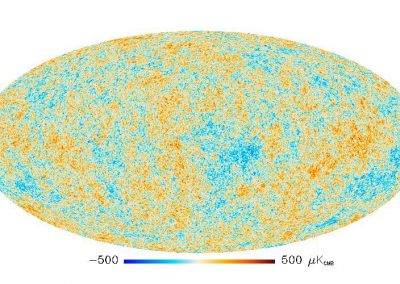
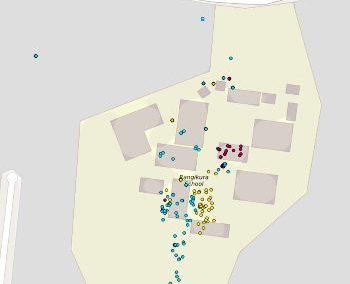
We demonstrate that our proposed language time series features can be successfully combined with standard machine learning approaches for natural language processing and have the potential to improve the classification performance. Furthermore, our suggested feature engineering approach can be used for visualizing differences and commonalities of stylometric features. This is demonstrated in Fig. 2, which shows discrimination maps for the first three principle components of the Spooky Books data set. The separation of the three primary colors demonstrates that the extracted features indeed capture differences between the three authors. The figures also indicate the location of two example sentences. The sentence indicated by the white cross was written by Mary Wollstonecraft Shelley: “’ Let me go,’ he cried; ’monster Ugly wretch You wish to eat me and tear me to pieces.” The sentence indicated by the plus symbol was written by HP Lovecraft: “The rabble were in terror, for upon an evil tenement had fallen a red death beyond the foulest previous crime of the neighbourhood.”

Figure 1: Interpreting short text samples as language time-series, allows to characterizing them with 3970 stylometric features from time-series analysis and signal processing, which can be used for an authorship attribution task. Figure adapted from (Tang et al., 2020, Fig. 6).
The sample from HPL is located in bins that are typical for both EAP and HPL and, therefore, are coloured in shades of purple (white plus in Fig. 2a,b). In Fig. 2c, the HPL example is located in a bin that is dominated by red, which indicates that the respective sentence resembles stylometric similarities with texts from EAP. The sample from MWS is located in a greenish bin in Fig 2b, but also has a strong resemblance with EAP and HPL, such that the white cross is located in reddish bins in Figs. 2a and 2c.

Figure 2: Discrimination maps for the first three principle components derived from 400 statistically significant language time-series features and 19,579 sentences of the Spooky Books data set. Red bins indicated stylometric features, which are dominated by Edgar Allan Poe (EAP), blue indicates HP Lovecraft (HPL), green indicates Mary Wollstonecraft Shelley (MWS). The white cross and the white plus symbol are discussed in the text. Adapted from (Tang et al., 2020, Fig. 4).
References
- Yichen Tang, Kelly Blincoe, and Andreas W. Kempa-Liehr. Enriching feature engineering for short text samples by language time series analysis. EPJ Data Science, 9(26): 1–59, 2020. doi: 10.1140/epjds/s13688-020-00244-9.
- Maximilian Christ, Nils Braun, Julius Neuffer, and Andreas W. Kempa-Liehr. Time series FeatuRe extraction on basis of scalable hypothesis tests (tsfresh – a Python package). Neurocomputing, 307:72–77, 2018. doi: 10.1016/j.neucom.2018.03.067.
- Alexander Hamilton, John Jay, and James Madison. The project gutenberg ebook of the federalist papers. In Project Gutenberg, number 1404 in EBook. ibiblio, Chapel Hill, North Carolina, 1998. URL http://www.gutenberg.org/ebooks/1404.
- Kaggle. Spooky author identification, 2018. URL https://www.kaggle.com/c/ spooky-author-identification/data.